阅前提醒:
本文可能使用了大量比较随便的英文表达;
本文的数学名词、公式可能不严谨;
总之意思传达到就行。
While doing the lab Backpropogation from week 3 of Math for ML course, some questions poped up in my mind.
Some background

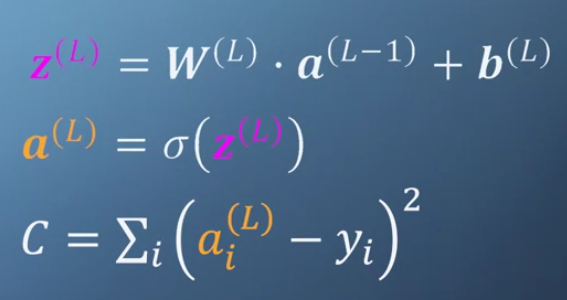
a(L) is the values of the nodes at layer L. a(L)=[a0(L),a1(L),…,am−1(L)], where m is the number of nodes at layer L.
z(L) is the values before passing to activation function, just a trick to make the derivation of the activation function easier.
W(L) is the weight from layer L-1 to layer L, and b(L) is the bias from layer L-1 to Layer 1.
σ is some activation function.
C is the cost function, yi is the truth value in the dataset for training the network, corresponding to a input ai(0)
What we want to do is to find good W(L) and b(L) that minimize the cost, and for that we need to take partial derivative of C with respect to each W and b.
Questions
In the lab Backpropogation, I doubted a partial derivative formula:
∂W(3)∂C=∂a(3)∂C∂z(3)∂a(3)∂W(3)∂z(3)
- Why we can take partial derivative of C with respect to W?
- In the cost function, it sums the squre of ai(L)−yi, why in the derivative formula it becomes the partial derivative of C with respect to a, and how?
Analysis
In the previous lectures, I’ve learned about chain rule for multivariate derivative with function being like this form:
f(x(t)),x=[x1(t),x2(t),...xn(t)]
f is a function of x1(t),x2(t),...xn(t), and each elements of x is a function of t, and in the end, f can be a function of t. Thus, we can try to find derivative of f with respect to t, by using multivariate chain rule:
Equation 1
dtdf=∂x∂fdtdx
Equation 2
dtdf=∂x1∂fdtdx1+∂x2∂fdtdx2+⋯+∂xn∂fdtdxn
The ∂x∂f and dtdx in Equation 1 are vectors, and dtdf is the dot product of these two vectors. The result of dot product just equals to the sum Equation 2. Therefore, we can use the simple form Equation 1.
The independent variable t is a single variable. However, what would the formula be if t is also a pack of variables? e.g.:
t=[t1,t2]
To make it easier for understanding, we can use an example, say x=[x1,x2], and t=[t1,t2],
f is a function of x, f(x), (or explicitly f(x1,x2), and each element in x is a function of t:
x=[x1(t),x2(t)]
or explicitly
x=[x1(t1,t2),x2(t1,t2)]
So, f can be a function of t1 and t2. Now, if we want to find derivative of f with respect to t, we have to do partial defferentiation on t1 and t2 respectively:
∂t1∂f=∂x1∂f∂t1∂x1+∂x2∂f∂t1∂x2
It can be written as dot product of vector
∂x∂f=[∂x1∂f,∂x2∂f]
and vector
∂t1∂x=[∂t1∂x1,∂t1∂x2]
Thus,
∂t1∂f=∂x∂f∂t1∂x
And similarly for t2
∂t2∂f=∂x∂f∂t2∂x
Until here, we can roughly answer a part of the question 1:
C is a function of a(L), and a(L) is a function of W(L) and b(L). Therefore, C can also be a function of W(L) and b(L).
Just like above example(f, t1, and t2), we can take partial derivative of C with respective W(L) and b(L).
However, there is new question:
W(L) is a matrix, how do we take derivative with respect to a matrix?
Key point: derivative with respect to each element in matrix/vector
My idea is that, this is just a simpler form for writing. We can’t take derivative with respect to a matrix or vector, but we actually do that on each element in the matrix or vector.
For the above example f, t1, and t2, we can also put ∂t1∂f and ∂t2∂f together in a vector, and write:
∂t∂f=[∂t1∂f,∂t2∂f]
Answer to the question
C is a function of a(L)=[a0(L),a1(L),…,am−1(L)].
Each ai(L) is a function of wi(L)=[wi,0(L),wi,1(L),…,wi,n−1(L)] and bi(L). n is the number of nodes in the layer L-1.
We, in fact, are not taking derivative of C with respect to the matrix W(L), but to each variable wi,j(L), while in the end, writing the result as simpler form ∂W(L)∂C.
Same for ∂a(L)∂C, we need to take derivative of C with respect to each variable ai(L), and in the end write as a simpler form.
So let’s start by doing derivative of zi(L) with respect to wi(L).
Expan the formula zi(L)=wi(L)⋅a(L−1)+bi(L):
zi(L)=[wi,0(L),wi,1(L),…,wi,n−1(L)]⋅[a0(L−1),a1(L−1),…,an−1(L−1)]+bi(L)
We can easily get the result of taking derivative of zi with respect to wi,j(L), it’s just aj(L−1). But let’s keep these derivative symbols (since the result is not important for our topic) and put all the derivatives in a vector:
Equation 3
∂wi(L)∂zi(L)=[∂wi,0(L)∂zi(L),∂wi,1(L)∂zi(L),⋯,∂wi,n−1(L)∂zi(L)]
And then we take derivative of ai(L) with respect to zi(L):
∂zi(L)∂ai(L)=σ′(zi(L))
Then we do ∂ai(L)∂C. Remember that:
C=i∑(ai(L)−yi)2=(a0(L)−y0)2+(a1(L)−y1)2+⋯+(am−1(L)−ym−1)2
We only take derivative with respect to ai(L):
∂ai(L)∂C=2(ai(L)−yi)
At last, we can get partial derivative of C respect to each wi,j(L)
∂wi,j(L)∂C=∂ai(L)∂C∂zi(L)∂ai(L)∂wi,j(L)∂zi(L)
All the derivative term ∂ai(L)∂C, ∂zi(L)∂ai(L), ∂wi,j(L)∂zi(L), are just scalars, so is the result ∂wi,j(L)∂C.
Now, what if we replace the single variable wi,j(L) with a vector wi(L)?
Then the last term becomes the Equation 3. It is a vector! The first and second term doesn’t change, because we still take derivative with respect to ai(L) and zi(L).
So what happens to ∂wi,j(L)∂C? It also turns to a vector!
∂wi(L)∂C=[∂wi,0(L)∂C,∂wi,1(L)∂C,⋯,∂wi,n−1(L)∂C]
What is wi(L)? It is the ith row of the matrix W(L). If we then do similar things to each row of W(L), and stack them together, we get a new matrix, that is ∂W(L)∂C!
∂W(L)∂C=⎣⎢⎢⎢⎢⎢⎢⎡∂w0(L)∂C∂w1(L)∂C⋮∂wm−1(L)∂C⎦⎥⎥⎥⎥⎥⎥⎤
Take away
When there is vector or matrix in a derivative formula, we are taking derivative with respect to each element in matrix or vector.